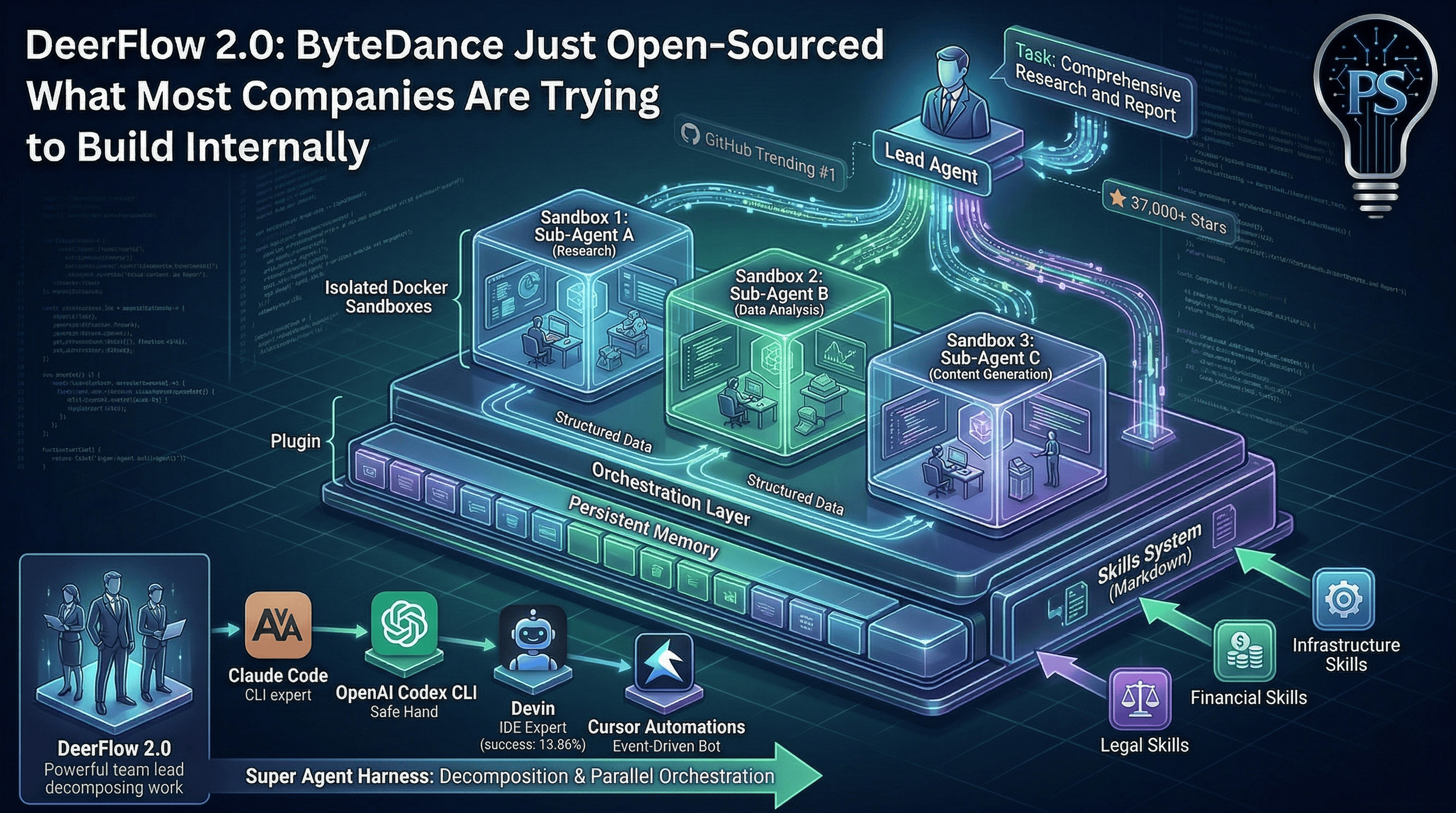

Most agent frameworks give you a chat interface with tool access. DeerFlow 2.0 gives the agent a computer.
ByteDance rebuilt DeerFlow from the ground up and open-sourced it in late February 2026. It hit #1 on GitHub Trending within days. As of this week it has over 37,000 stars and 4,400 forks. The community is excited. But most of the coverage I’ve seen misses what actually makes this interesting.
DeerFlow isn’t a research tool with a nice UI. It’s a super agent harness. The difference matters.
What “super agent harness” actually means#
The term sounds like marketing, so let me break down what it does in practice.
A typical agent framework lets you chain LLM calls with tool use. You give the model access to search, file reading, maybe code execution. The model decides what to do step by step. That’s what most people mean when they say “agent.”
DeerFlow does something architecturally different. A lead agent receives a task, decomposes it into sub-tasks, and spawns specialized sub-agents that run in parallel. Each sub-agent gets its own isolated context, its own tools, and its own termination conditions. They work concurrently, report structured results back to the lead agent, and the lead synthesizes everything into a coherent output.
That’s not a chain. That’s an orchestration layer. And the execution doesn’t happen in an LLM’s imagination. It happens inside an actual sandbox.
The sandbox is the real differentiator#
Each DeerFlow task runs inside an isolated Docker container with a full filesystem. The agent can read files, write files, execute bash commands, run Python scripts, and manipulate outputs. There’s a virtual path system that prevents the agent from seeing real host paths, which blocks path traversal attacks.
The directory structure per thread looks like this:
/mnt/user-data/
├── uploads/ # your files
├── workspace/ # agent's working directory
└── outputs/ # final deliverables
This is the difference between “the model says it would write a file” and “the model actually wrote the file.” When DeerFlow generates a report, builds a slide deck, creates a website, or runs a data pipeline, the output exists as actual files in an actual filesystem. Not text in a chat window.
That matters because it means DeerFlow can handle tasks that take minutes to hours. A research task fans out into a dozen sub-agents, each exploring a different angle, and converges into a single report. Or a website. Or a deck with generated visuals.
The skills system#
DeerFlow’s capabilities are defined as “skills,” which are structured Markdown files containing workflows, best practices, and references to supporting resources. The framework ships with skills for research, report generation, slide creation, web page generation, and image/video creation.
The clever part is progressive loading. Skills only get injected into the agent’s context when the task needs them. This keeps the context window lean, which matters when you’re running sub-agents in parallel and every token counts.
You can add custom skills, replace built-in ones, or combine them. The skill system is essentially a plugin architecture defined in Markdown. It’s simple enough that someone who isn’t a framework developer can extend it.
How it compares#
The landscape is crowded, so here’s where DeerFlow sits relative to tools engineers are actually using:
Claude Code is a terminal-based CLI agent. Powerful for deep coding sessions, strong reasoning, MCP support. But it’s fundamentally a single-agent tool. You start it, it works, it finishes. DeerFlow orchestrates multiple agents in parallel with isolated contexts. Different architectural layer.
OpenAI Codex CLI runs in a sandboxed microVM with strong safety guarantees. Fast, cost-efficient, good for GitHub workflows. But it’s scoped to coding tasks. DeerFlow handles research, content generation, data pipelines, and arbitrary multi-step workflows.
Devin positions itself as an autonomous “AI software engineer” with a full IDE. But benchmarks show a 13.86% official success rate and it’s the slowest option in head-to-head tests. DeerFlow’s parallel sub-agent architecture is fundamentally more efficient for complex decomposable tasks.
Cursor Automations, which I wrote about this week, takes a different approach entirely: event-driven triggers that launch agents automatically. DeerFlow is more of a task-delegation platform. Cursor is more of an always-on operational layer. They could complement each other.
The closest analogy might be: Claude Code is your best individual contributor. Codex is your safe pair of hands for PRs. Cursor Automations is your on-call bot. DeerFlow is the team lead who decomposes the project and assigns the work.
What engineering leaders should notice#
Three things stand out to me.
First, the architecture is what most internal AI platform teams are trying to build. Sub-agent orchestration, sandboxed execution, persistent memory, a skills/plugin system, support for multiple models and deployment modes (local, Docker, Kubernetes). If you’re an engineering leader thinking about building an internal agent platform, DeerFlow is either your starting point or your benchmark.
Second, it’s ByteDance. That means serious engineering resources behind it. But it also means you should do your own security review before running it anywhere near production data. The code is MIT-licensed and open source, which is great. But “open source from a large tech company” and “audited for your threat model” are different things. Read the code. Check the network calls. Understand what telemetry exists. The same advice applies to any framework you’d run in Docker containers with filesystem access.
Third, the skills system is the part with the most long-term potential. Right now it ships with research and content generation skills. But the architecture supports arbitrary capabilities defined in Markdown. That means the community can build and share skills for specific domains: legal research, financial analysis, infrastructure automation, compliance workflows. If the ecosystem develops, DeerFlow becomes a platform, not just a tool.
The honest assessment#
DeerFlow 2.0 is impressive engineering. The sandbox execution model, parallel sub-agents with isolated context, and progressive skill loading are genuine architectural innovations in the open-source agent space. It’s more production-oriented than most frameworks I’ve seen.
But it’s also early. The documentation has gaps. The learning curve is steep. Running multiple specialized models requires significant compute. And the project is moving fast enough that what you read about it this week might be outdated next week.
If you’re evaluating it for your team, my advice: clone it, run it locally, throw a real multi-step task at it, and see how it handles decomposition, failure recovery, and output quality. Don’t evaluate it from the README. Evaluate it from the sandbox.
The agent framework landscape is moving fast. DeerFlow just raised the bar for what “open source” means in this space. Whether it becomes the default depends on whether the community builds the skills ecosystem and whether ByteDance sustains the investment.
37,000 stars in a few weeks says the interest is real. Now we’ll see if the execution holds.
Experimenting with DeerFlow or building your own agent orchestration? I’d love to hear how you’re approaching it. Find me on X or Telegram.