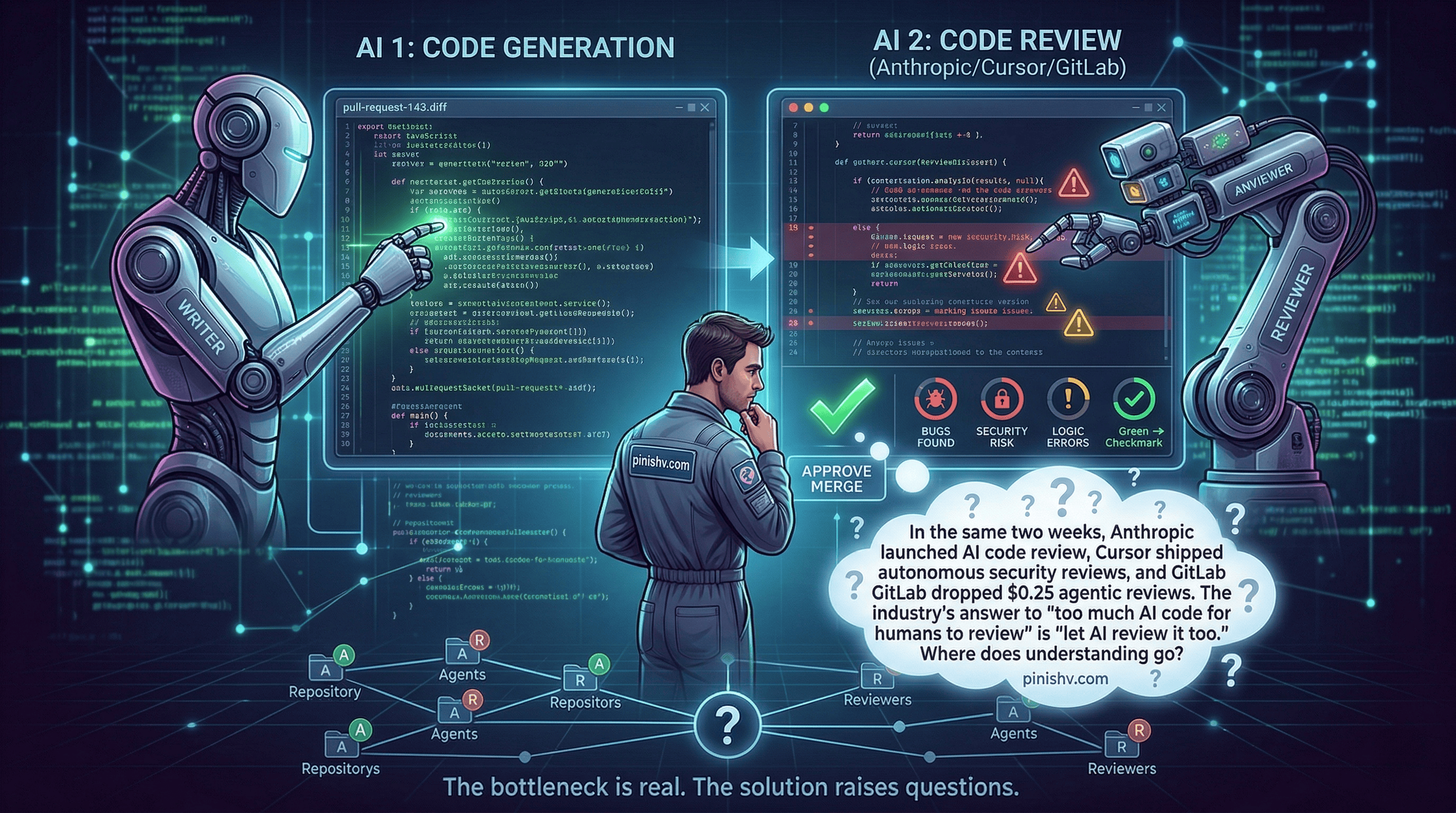

Three things happened in the first two weeks of March 2026.
Anthropic launched Code Review for Claude Code. A multi-agent system that automatically reviews GitHub pull requests, dispatching specialized agents that analyze code for bugs, security issues, and logic errors. Internally at Anthropic, 54% of PRs now receive substantive review comments, up from 16%.
Cursor shipped Automations with security review triggers that fire on every code push. No human initiates the review. The system does.
GitLab made agentic code reviews available at $0.25 per review, including false positive detection for security scanning.
The industry is converging on the same answer to the same problem: AI generates more code than humans can review, so AI should review it too.
That answer is partly right. And partly something we should think harder about.
The bottleneck is real#
Anthropic’s own numbers make the case. Their code output grew 200% year-over-year, but their human review capacity didn’t. That’s not unique to Anthropic. Any team using AI coding tools aggressively is hitting the same wall. More PRs, same number of reviewers, reviews get thinner.
The Plandek 2026 benchmarks across 2,000+ teams confirmed this: as AI speeds up coding, the bottleneck shifts downstream to review, testing, and integration. Bottom-quartile teams take 35+ hours to merge a pull request. That’s not a coding problem. That’s a review problem.
So AI code review tools are solving a real constraint. And early results are genuinely impressive. Anthropic reports less than 1% of Code Review findings are marked incorrect by engineers. On large PRs (1,000+ lines), 84% receive findings averaging 7.5 issues per review. That’s catching things humans were missing because they didn’t have time to look carefully.
The part that should make you think#
Here’s my concern.
If AI writes the code and AI reviews the code, the human becomes the person who approves the merge. Not the person who understands the change. The approver.
That’s a fundamentally different role than reviewer. A reviewer reads, questions, understands, and decides. An approver looks at the green checkmarks and clicks the button.
I wrote this week about how the culture shifted toward rewarding speed over understanding. AI code review accelerates that shift. Not because the tools are bad, but because they make it even easier to ship code nobody on the team truly understood.
When the AI-generated PR gets an AI-generated review with AI-generated test suggestions, and a human clicks “approve” because all the signals are green, what exactly did the human contribute? And when that code breaks at 2 AM, who debugs it?
The right way to use this#
I’m not arguing against AI code review. The bottleneck is real, and these tools catch things humans miss. Arguing against them would be arguing for worse code.
But I think the right approach is to treat AI review as a first pass, not the final word. Let the AI catch the mechanical stuff: unused variables, security patterns, style violations, common bugs. That frees human reviewers to focus on the things AI is still bad at: architectural fit, business logic correctness, failure mode analysis, and whether the approach makes sense given context the model doesn’t have.
The worst outcome is AI review replacing human review entirely. The best outcome is AI review making human review more focused and more valuable.
The difference depends on whether your team treats the green checkmark as the end of the process or the beginning of a better conversation.
That’s a culture decision, not a tooling decision. And based on what I’m seeing across the industry, most teams haven’t made it consciously.
Using AI code review on your team? Seeing it change how humans review? I’d love to hear how it’s working. Find me on X or Telegram.